How to workaround "Import failed" error in Medium with debugger
Hacking the “Import your story” in debugger for proper backdate
Originally posted in LikeCoin medium publication.
tldr: If you just want a Medium Story Backdating tool
If you just want to control the publish date of your story, use my new Medium Backdating Tool.
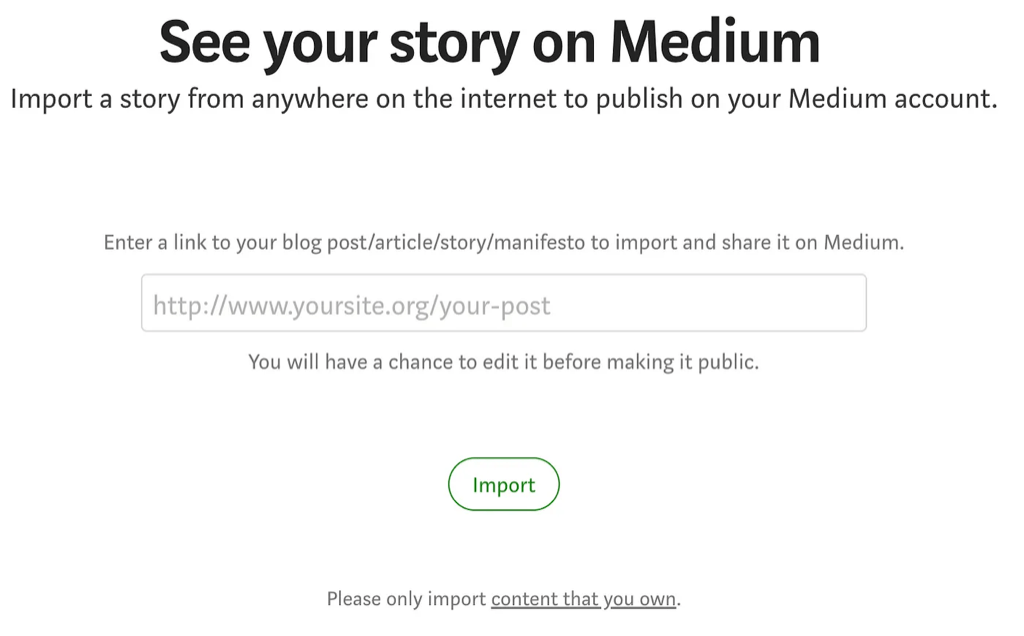
Import story tool
Medium has a powerful feature that allows you to import websites you own into stories. All you need to do is to provide an URL then press Import. Check it out if you haven’t tried it before.
You might ask “Why should we use import though?”. The Medium editor is so easy to use and powerful (kudos to the editor developers) that it can handle pasting from external sources very easily. It often takes a simple copy-and-paste to post any articles from my WordPress site to Medium.
However one significant difference is the “import story” feature parses the published date and canonical link of the original website, then sets them accordingly in the Medium story. On the other hand, you cannot change the published date of any manually pasted story. The published date would be set as the time you post the pasted story in Medium.
Backdating the published date is an important issue when you are trying to sync articles in batches from existing websites to a Medium publication. You don’t want to bomb subscribers with notifications of stories that are months old, or flood the publication page with post from 2022.
Import fail!
So when I see this error when importing posts from our WordPress site, I know I am screwed.
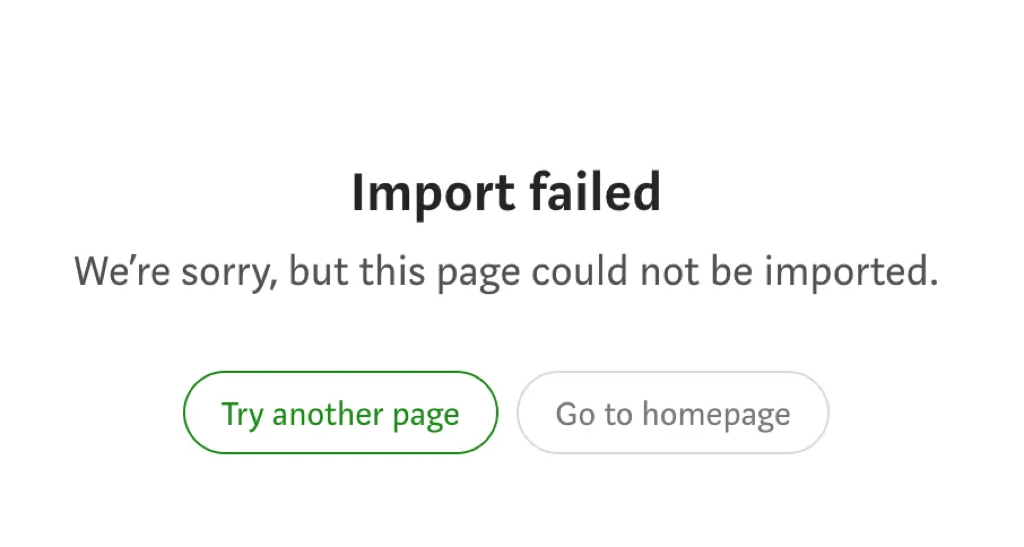
There is no useful error message as in why the import failed. Medium document simply states that if the service fails, it fails, and tells you to paste the content instead. As mentioned earlier, it is not feasible for me to manually post all stories without backdating. A simple Google search reveals that it is possible to force a backdate, but it requires using a placeholder page containing the published date metadata. In the case of articles, this can be accomplished by pushing the placeholder page to a Github repository.
As a developer, I am too lazy to host a page and manually set the dates for each post I need to import. Lets try digging into the Medium import error page and see if we can find out the actual cause of the failed import. We will be using Chrome’s developer tool.
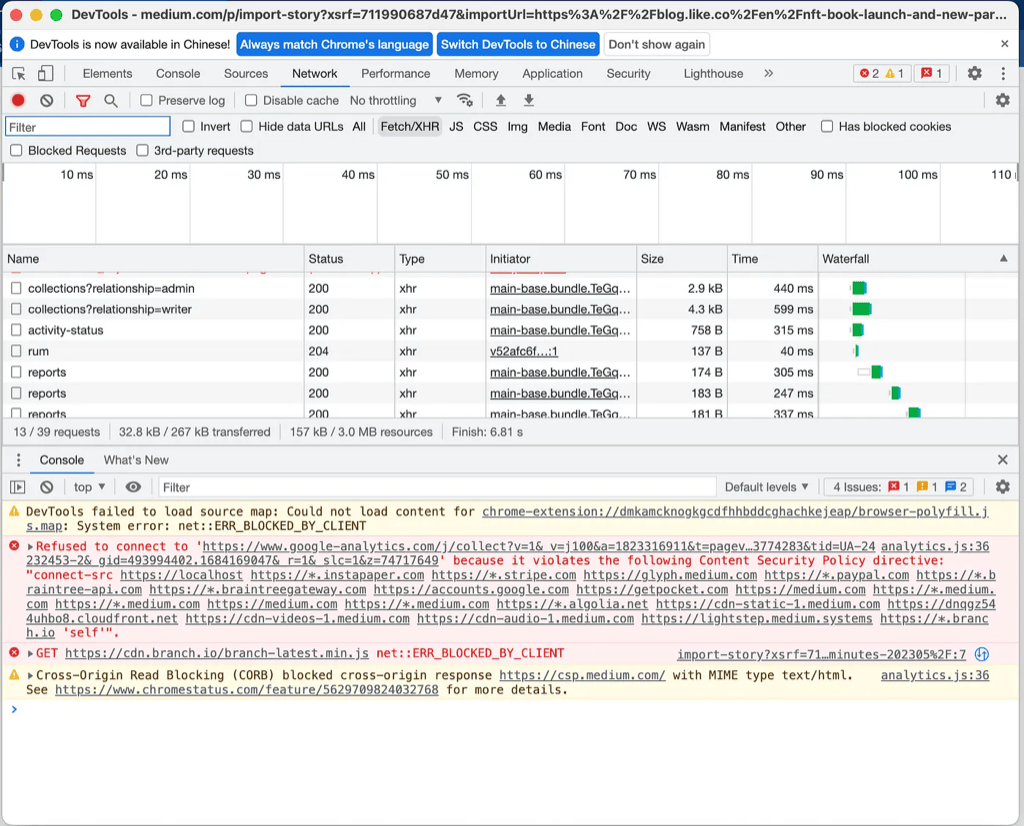
First thing one would look at would be the console, any JavaScript or API call errors should be shown here. However as seen in the image, only some boring message about CSP is shown, so no luck in the console.
Second thing to look for would be in the Network tab. Since Medium uses a third party service for parsing and importing external website, one would expect some external API is called. We can filter the network request to “Fetch/XHR” to only show API calls, and see if anything interesting shows up. However, there is no failed HTTP requests. Most of the request are analytics events. By inspecting the payload and response one by one though, a particular API call seems interesting.
oh-noes
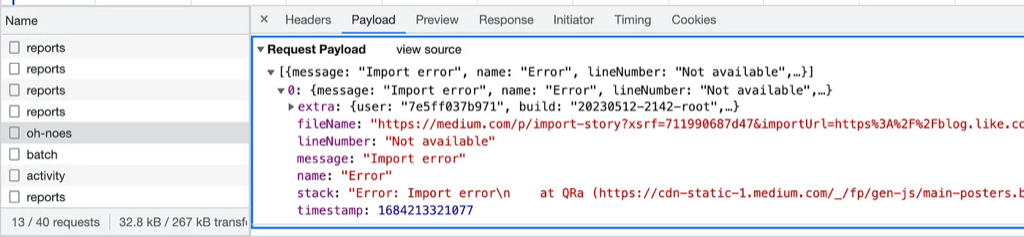
The endpoint is called /oh-noes and the request payload looks exactly like a Javascript error stack. This seems to be some home brew error logging API (we all know Sentry is expensive). The stack value inside the payload points to an “Import Error” throw by the Javascript file /main-posters.bundle.${hash}.js , the exactly location of the file and the line number is also shown. By digging into the source of this file, we can trace the origin of the import error that is troubling us. To view the source of js in Chrome, go to Sources tab of the developer tools, then find the js file according to the path shown in the stack payload.
Debugger
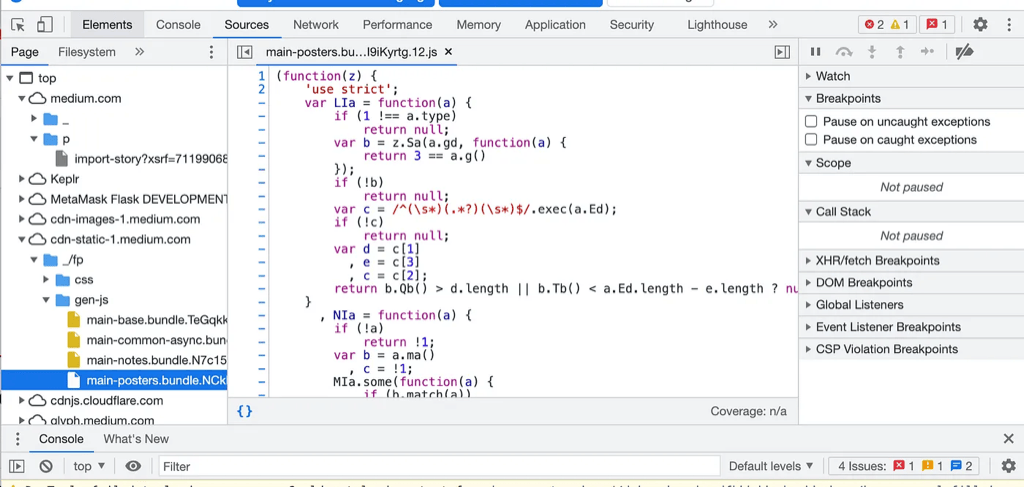
It is a obfuscated JavaScript file, as expected in most modern web application. All the variable names are shortened, functions names and structure are messed up for improved size and performance. Let us just skip straight to the interesting part by searching the function name QRa and line number mentioned in above error payload.
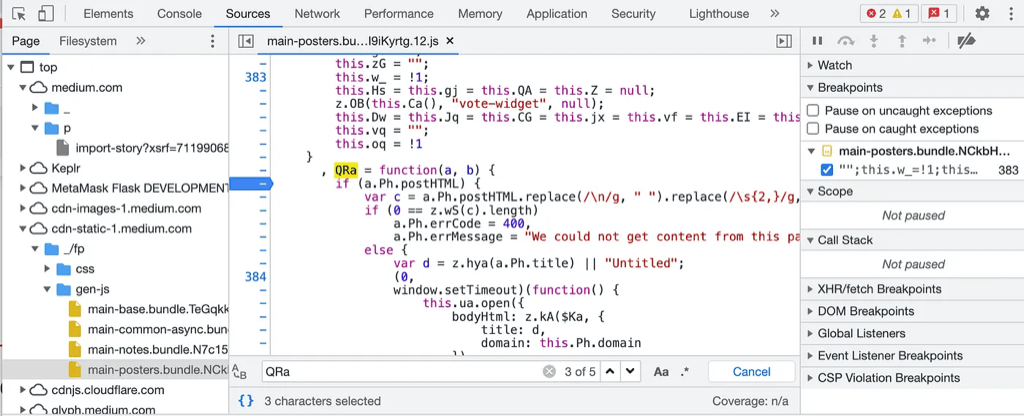
Finally something promising show up. We see words like “postHTML”, also a “errorCode” that is set to 400, which probably hints it is a HTTP error code. Going a few more lines below allows us to see how Medium show different error messages for some error codes it encounters.
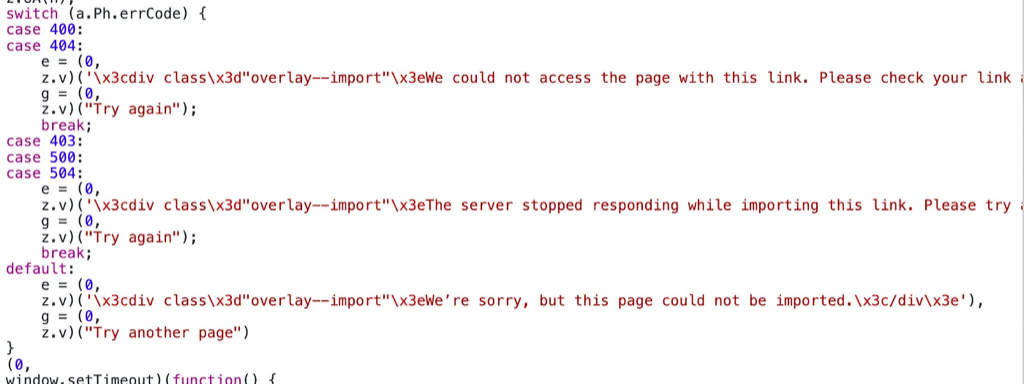
As we can see above, there are three kinds of import error. One for 400/404 error, one for 403/500/504 error, and one that catches all error. We can assume errCode is the HTTP error code encountered by the importer when crawling the target URL. Unfortunately, the error message we see in our import error page is the catch-all case. To understand the actual errCode for our case, we would want to know about the state of the a.Ph variable during our import. To achieve this, we can set a breakpoint on QRa .
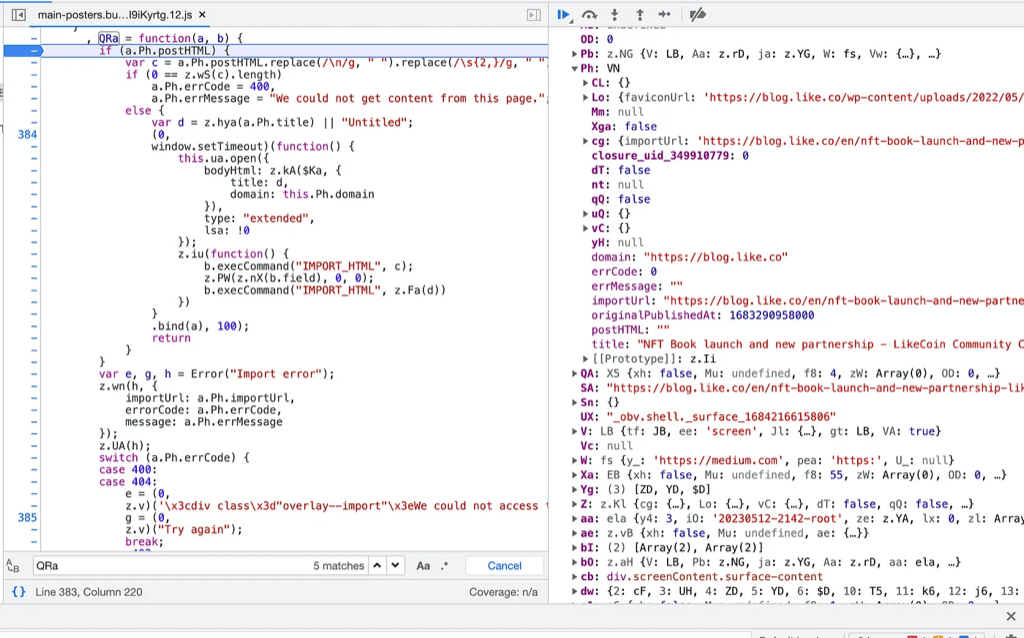
After setting a breakpoint, retry the import flow by refreshing the browser. The page execution will pause when it reaches the breakpoint we set. On the left we can see where the JavaScript execution was paused; on the right we can see the content(state) of all the variables when the JavaScript reaches the breakpoint. The variable we are interested in is a.Ph (note that it is case sensitive).
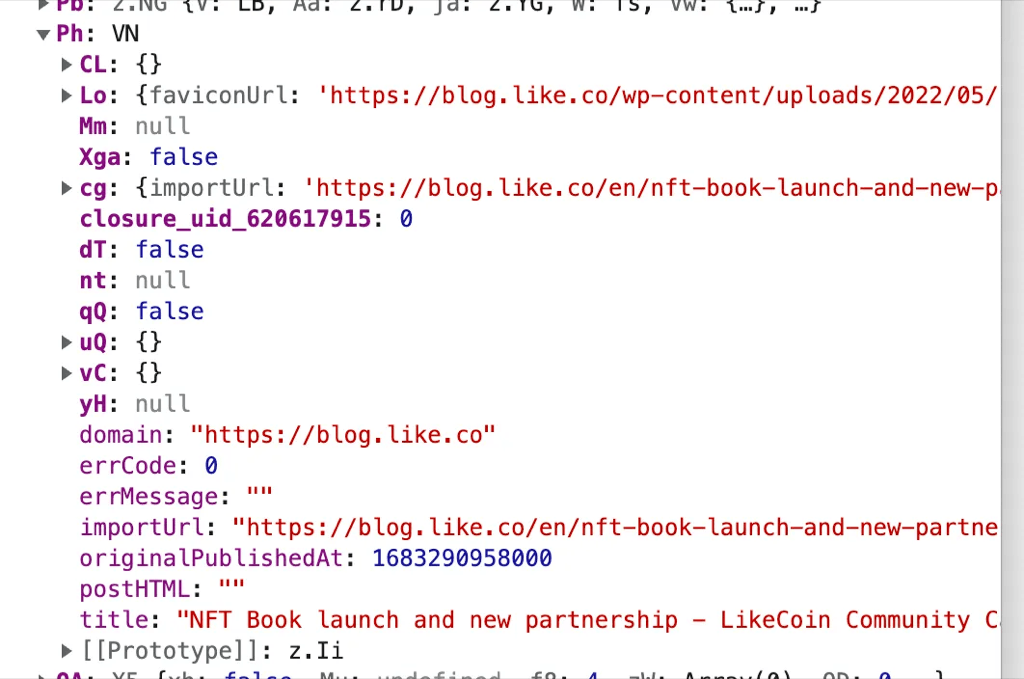
Unfortunately we can see the errorCode is 0, which means we don’t know why the import fails. However a very interesting observation is that all the fields except postHTML is properly filled. As we can see in the source, having a.Ph.postHTML empty would throw us into an error case. What if we actually fill in some random text for postHTML here? Actually we can do that!
Hacking values in debugger
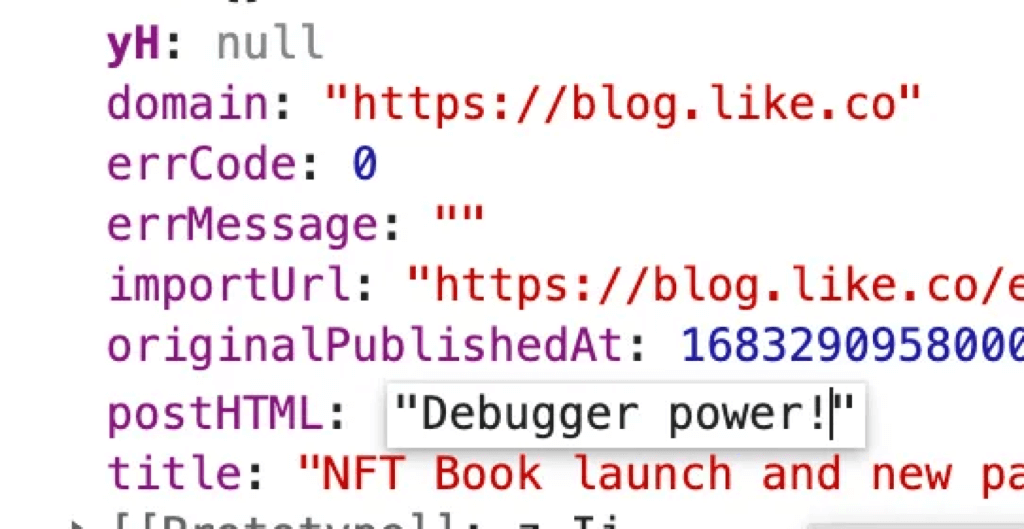
Double click on the postHTML key, it would become editable. Type in a random text enclosed with "" for it to be a proper string. Continue the page JavaScript execution by pressing continue in the Chrome developer tool popup.
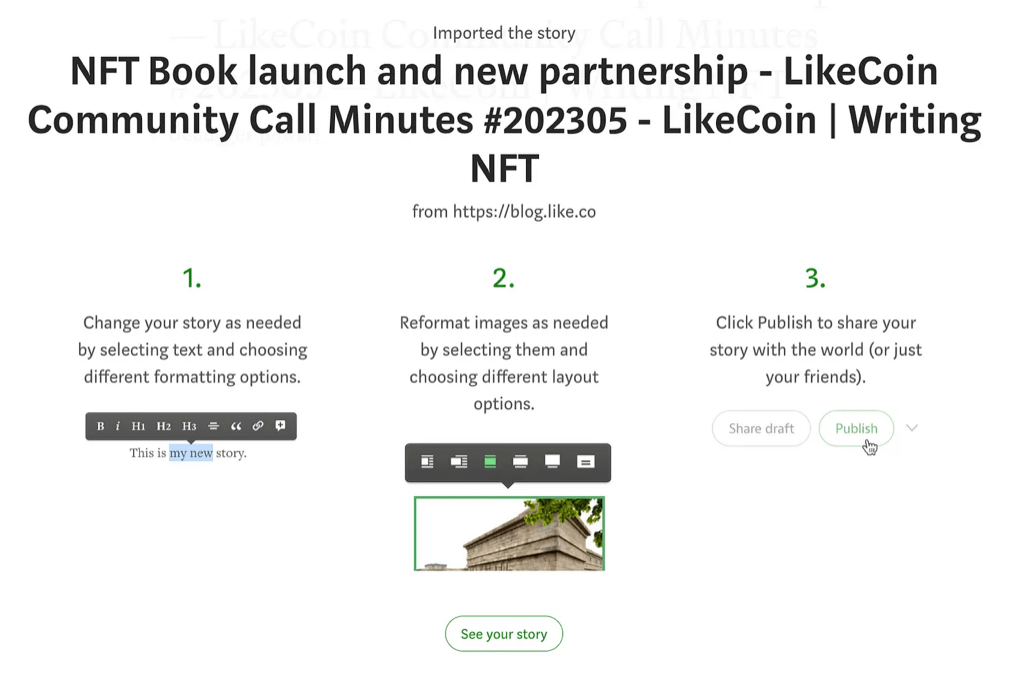
It’s working, or not?
Voila! The error is gone! But what do we actually get as the result?

The text we just entered in postHTML would show up as the story content!
Well thats not ideal for import, but remember that:
The importer actually successfully crawled all the metadata required for import, except postHTML . That can be seen in debugger.
Medium editor is very powerful at handling pasted content
Lets try copy and pasting the content from the original site…

Perfect. The best part of this is the publication date and canonical link would automatically be set according to the target URL. No pushing and editing needed!
Result
The result of importing multiple article from 2022 is shown below. Welcome to browse our publication or our more updated site.
Shoutout to Medium for the powerful and friendly story editor. But it would be nicer if the import story features can show more useful error message!
TL;DR
if your import fails with unknown error, but you really need those backdates:
- Import URL and fail once
- Check the JS source of Import Error by viewing
/oh-noespayload - Breakpoint on the origin of the Import Error
- Set a random non-empty
postHTMLto bypass the error screen - Paste back the actual content
- Publish!